Tutti i modelli sono sbagliati, ma alcuni sono utili (G. E. Pelham Box). Il modello di funzionamento dei Large Language Model (LLM) presentato recentemente in A Categorical Analysis of Large Language Models and Why LLMs Circumvent the Symbol Grounding Problem (Luciano Floridi, Yiyang Jia e Fernando Tohmé) potrebbe essere uno di quelli semplicemente sbagliati.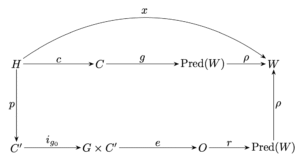
Nel paper si afferma che i chatbot basati su Large Language Model sono costitutivamente inclini a enunciare proposizioni (frasi che possono essere vere o false) che un Umano respingerebbe senza indugi. Parliamo delle famose “allucinazioni”. Questo comportamento sarebbe riconducibile alla loro incapacità di fare “grounding”, cioè basare le proposizioni su un Mondo al quale, in quanto automi, non hanno accesso.
Il modello adotta, con un ricco apparato formale, il framework della logica epistemica (Hintikka, 1962). Troviamo l’insieme W dei “mondi possibili” (stati di cose) e quello P(W) delle proposizioni che li riguardano. La semantica è quella della logica: “la neve è bianca” se e solo se, a giudizio dell’Umano, la neve – guarda là – è proprio bianca. Benché questo corrispondentismo possa apparire ridicolmente inadatto al linguaggio naturale (e i logici lo sanno benissimo), questo non è il problema. I modelli, necessariamente, fanno astrazione da qualcosa, altrimenti sarebbero essi stessi il Mondo. Che Qualcuno nel Mondo possa avere la Verità in tasca è un’idea stravagante, ma, se è necessario assumerla in un modello utile, possiamo benissimo farlo, mettendo un attimo da parte le miserie doxastiche dell’umanità, dovute al fatto che ciascuno tiene in tasca la verità sua.
Il problema, a mio avviso, è quello di suggerire che l’automa sia incline a generare proposizioni allucinatorie come “la neve è nera” in conseguenza della mancanza di accesso al Mondo (il “grounding” appunto).
Traduco:
[…] la tesi centrale è che gli LLM non hanno accesso immediato a W [il Mondo] e quindi (therefore) non risolvono il problema del grounding dei simboli. Piuttosto, lo aggirano (circumvent) sfruttando contenuti umani già fondati [interpretati].
Nel modello, la mancanza di grounding non è presentata come una causa contingente, ma come una condizione strutturale che renderebbe inevitabili i fallimenti degli LLM. Se accettassimo di interpretare questa come causa efficiente, in termini proposizionali, convenendo di indicare con G il grounding e con A la possibilità di allucinazioni, potremmo formularla così:
non-G → A
(la mancanza di grounding implica la possibilità di allucinazioni)
Da questa asserzione tuttavia, per modus tollens, seguirebbe immediatamente:
non-A ⊢ G
(l’impossibilità di allucinazioni implica il grounding)
Se il nesso fosse davvero causale, basterebbe dunque costruire un chatbot non allucinato per poter concludere che esso ha in effetti accesso al Mondo. Ma non è questa la tesi che Floridi et al. intendono sostenere. Al contrario, l’intero loro argomento poggia sul presupposto che agli automi tale accesso sia inerentemente precluso. In particolare, oltre ad un corpo e ad un buon vocabolario enciclopedico, ciò che mancherebbe agli automi è un grounding normativo-sociale. Il linguaggio vive nello spazio delle ragioni (Sellars, 1956): usare una parola significa assumere impegni, esporsi a correzioni, offrire giustificazioni. Il “vero significato” richiede dunque una forma di responsabilità, e questa appartiene a una dimensione umana che le macchine, per costruzione, non possono abitare. E se riuscissero a non allucinare, sarebbe per qualche altro motivo.
Se la mancanza di accesso al Mondo è causa di allucinazioni, ma non avendo queste ultime non potremmo comunque dire di aver accesso al Mondo, allora c’è da chiedersi se valga la pena indagare il nesso causale. Forse, l’accesso al Mondo e l’amore per la Verità sono variabili indipendenti. Il paper tuttavia si focalizza proprio su una complessa spiegazione causale: l’LLM è un sistema di statistical pattern completion che, per il carattere stocastico dell’inferenza, può produrre sequenze linguisticamente plausibili ma fattualmente false. Poiché manca di grounding, la macchina non dispone di un criterio interno per distinguere tra plausibilità statistica e verità; per questo le allucinazioni risultano strutturali e non puramente accidentali. Si tratta, apertis verbis, del noto argomento del “pappagallo stocastico” (Bender et al. 2021).
Anche se l’automa fosse strumentato con procedure deterministiche, come ad esempio l’accesso a basi di conoscenza certificate o a contenuti strutturati, e le allucinazioni fossero drasticamente ridotte, il sistema non entrerebbe, secondo gli autori, nello spazio delle umane ragioni. Ma tenendo fermo questo punto, il modello dovrebbe essere, a mio avviso, riconsiderato. Se in fin dei conti quello che ci interessa è la conoscenza (episteme), bisognerebbe spiegare perché quelle procedure non offrirebbero garanzie equivalenti a quelle normalmente ottenibili dagli umani. Oppure dire chiaramente che la questione non è epistemologica e operativa: in gioco c’è ben altro. Cosa?
Ora, l’integrazione sistematica di fonti verificate, strumenti di ricerca, basi di dati e moduli simbolici è precisamente lo scenario verso cui stanno evolvendo i sistemi attuali. Questo ridimensiona notevolmente la natura stocastica del loro eloquio. Gli autori ne sono consapevoli, ma liquidano la questione come un trascurabile dettaglio:
Traduco:
Abbiamo osservato che i sistemi effettivamente distribuiti, inclusi quelli di AI agentica, possono utilizzare strumenti (ad es. ricerca, esecuzione di codice, basi di dati) o modalità aggiuntive (visione, audio), ampliando così il contenuto disponibile in un dato momento di inferenza. […] Questo, di per sé, non risolve il problema del symbol grounding; si limita ad ampliare il contenuto consultato.
Qui il modello ha un problema tecnico piuttosto serio. Non è corretto sostenere che il ricorso a basi di conoscenza esterne, anche espresse in forma “ontologica” come nel caso dei Knowledge Graph, costituisca un semplice ampliamento del contenuto già presente nel modello. Si tratta piuttosto di rappresentazioni condivise a priori tra esseri umani e sistemi artificiali, appartenenti non solo alla tradizione dell’AI simbolica, ma più in generale a quella delle basi di dati e dei sistemi informativi. A differenza dei parametri neurali, queste rappresentazioni sono pubbliche, criticabili, modificabili, in quanto semanticamente definite e stipulate.
Ad esempio, immaginiamo un LLM strumentato con servizi meteo accessibili attraverso il web – proprio quelli che consultiamo ogni mattina con fiducia. Alla domanda:
Piove a Parigi?
un LLM siffatto non cercherebbe di produrre su base statistica un “sì” o un “no”. Piuttosto, genererebbe l’invocazione dei servizi (tool nel gergo tecnico) con parametri che possiamo immaginare come:
LOC=PARIS, TIME=TODAY
I tool, verosimilmente, risponderebbero con tabelline orarie delle previsioni del tempo a Parigi, che fornite come contesto (incidentalmente, qualcuno lo chiama “ground truth”) porterebbe il chatbot a produrre una risposta. Ecco cosa dice ora GPT 5.2:
No: al momento non sta piovendo a Parigi e le previsioni non danno pioggia consistente nelle prossime ore — prevalgono cielo nuvoloso o variabile senza precipitazioni significative. Le probabilità di pioggia sono basse o molto deboli nella maggior parte della giornata e della serata. (AccuWeather)
In sintesi:
-
cielo nuvoloso con schiarite, pioggia assente o molto debole oggi; (AccuWeather)
-
alcune previsioni segnalano possibili deboli rovesci notturni, ma nulla di rilevante al momento; (3BMeteo | Previsioni Meteo)
-
probabilità di precipitazioni rimane bassa (intorno al 20–25 %). (AccuWeather)
Quindi se sei o stai guardando il meteo di Parigi: puoi uscire senza ombrello (per ora).
Notate il nome dei tre tool effettivamente usati. Cosa c’è di deteriore rispetto a quello che avrei saputo accedendo direttamente alle tre app e integrando a mente i risultati? Sarei piuttosto propenso a dire che, pur fuori dallo spazio delle ragioni, il chatbot mi abbia reso un buon servizio, epistemicamente parlando. Moltiplicate questo esempio per tutti i tool informativi che vi vengono in mente, dagli orari ferroviari alle ricette di cucina, e avrete un’idea abbastanza precisa di quello che questi sistemi stanno diventando. La conoscenza viene per lo più attinta non direttamente dai modelli, ma da fonti documentali, basi di dati, servizi online: gli ingredienti della nostra normale dieta informativa. Sempre più spesso, i modelli linguistici si limitano a fare ciò che il loro nome suggerisce: contribuire conoscenze linguistiche in processi di information processing molto articolati, le cui procedure, pur celate nei meandri di giganteschi servizi software, benché euristiche (dunque sostanzialmente abduttive), sono comunque razionali.
I pappagalli stocastici sono volati via. Al loro posto sono arrivati i corvi epistemici. Un compito interessante per chi ama la logica modale (doxastica, però) sarebbe quello di capire come risolvere gli eventuali clash tra sorgenti di dati paritarie e divergenti. Che succede se uno dei tre servizi meteo di cui sopra mi dice che a Parigi nevica? Il tema non è nuovo.
Tutti i modelli sono sbagliati, e quello in questione non lo è di meno. Ma a me sembra – con tutto il rispetto e l’ammirazione per il grande lavoro e la calligrafia formale degli autori – che sia di scarsa utilità, almeno nel mio understanding. In conclusione gli autori dicono: usateli pure ‘sti chatbot (tanto lo fate comunque) ma statevi accorti. Più o meno quello che già si sapeva.


